To partition n observations into k clusters with the nearest mean, serving as a prototype of the cluste
hierarchical
To produce a set of nested clusters organized as a hierarchical tree
manual
Manually separating these data points into different risk level, change level and volume level
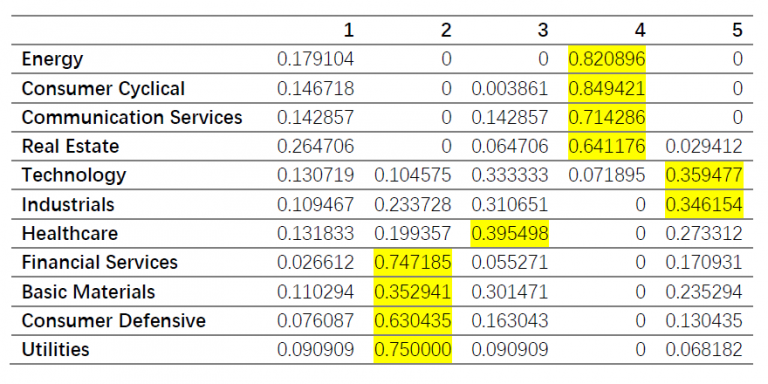
Kmeans
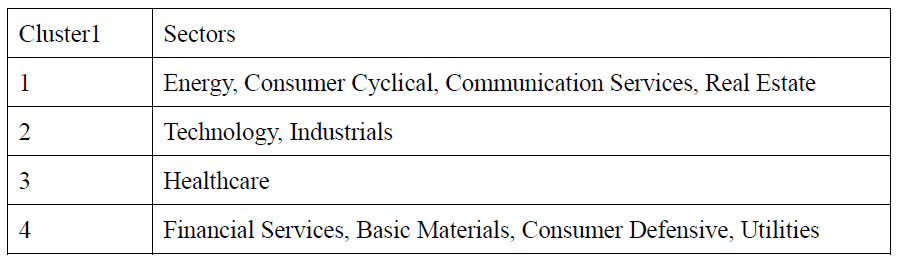
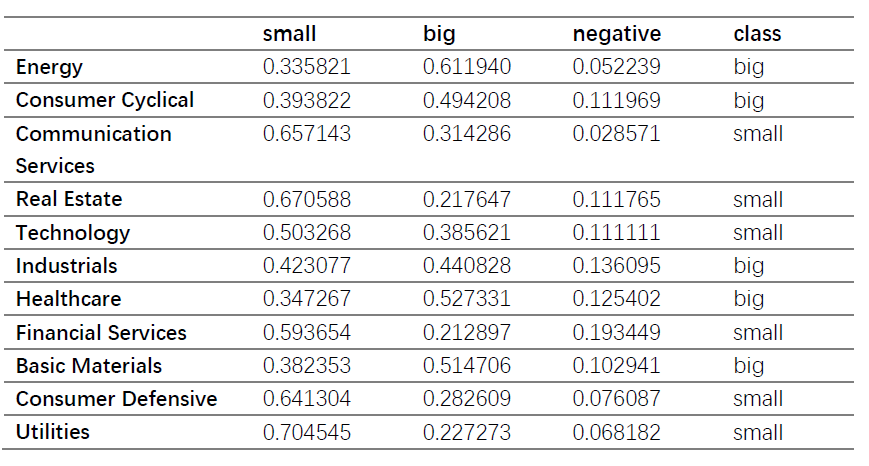
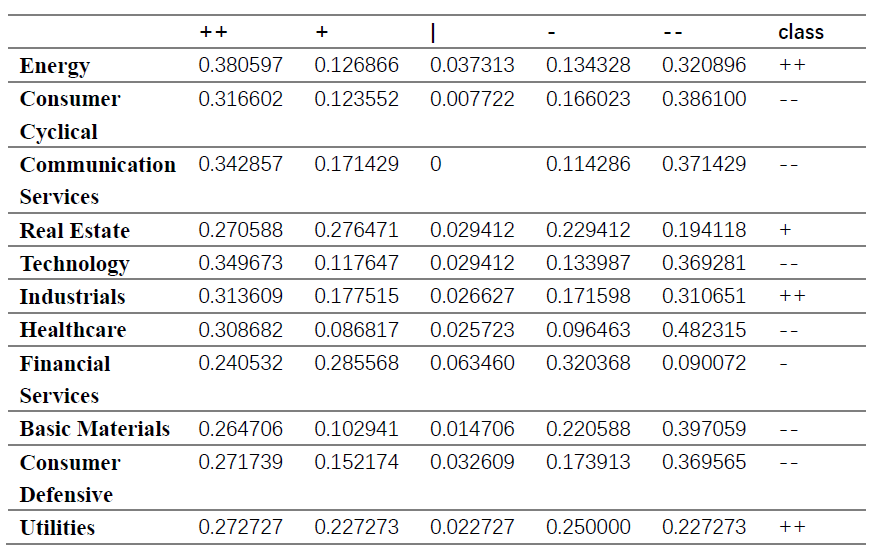
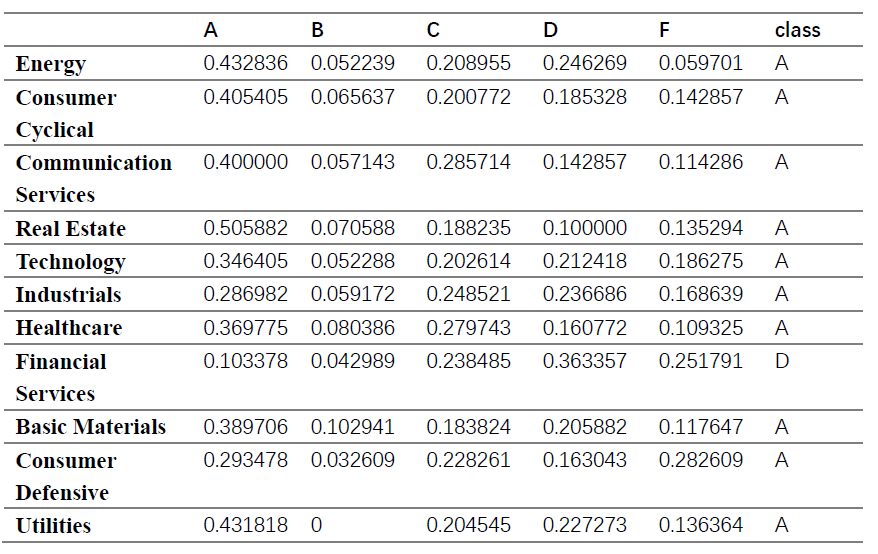
After finding out the proportion for each sector in each label, we got 4 final groups showed in the table.
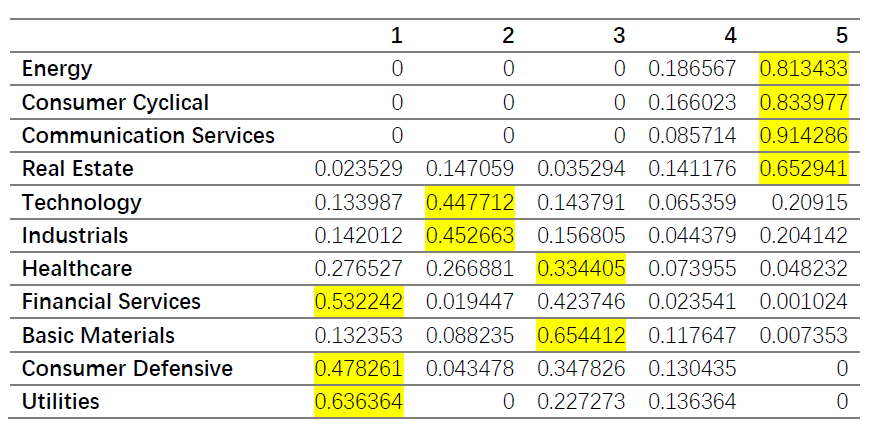
Hierarchical
We repeated the work for hierarchical.
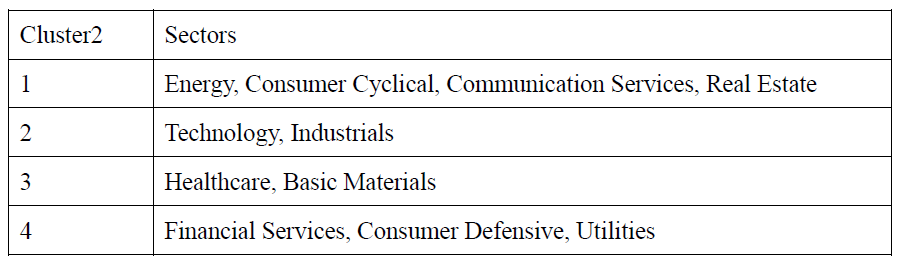
and we got 4 final groups showed in the table.
Comparing these two results, it is not hard to find that they are quite similar since both methods divide 11 sectors into four groups and the only difference is the belonging of this sector-‘Basic Material’. However, after a close look at the results, it seems that there is no obvious similarities among those sectors in the same group. Like financial services, consumer defensive and utilities, they are three totally different kinds of industries and they are not supposed to be in a group(from the facts of introduction). Therefore, our results seem to be not as good as our expectations.
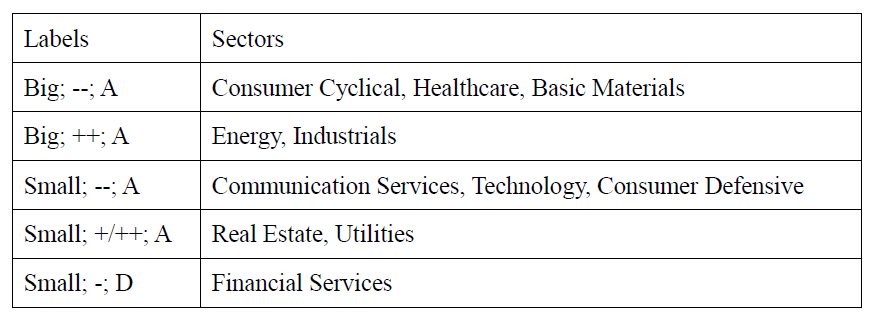
Finally, we decided to manually separate data by the same three variables we used in previous two methods- risk level, year to date change level and volume level, to see if the result is better than these two methods.
Manually
We got 5 groups by manually clustering and each group has three labels, which shows the level of the three categorical variables. Take the first row as an example, we concluded that consumer cyclical, healthcare, basic materials are in a group that has big risk level, ‘–‘ change level and ‘A’ volume level.