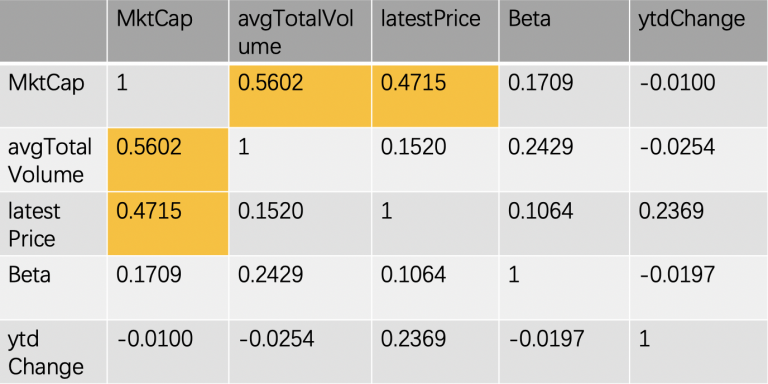
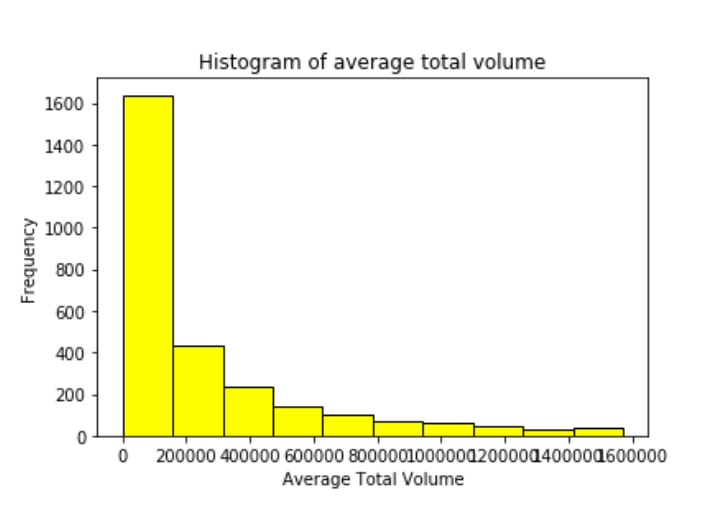
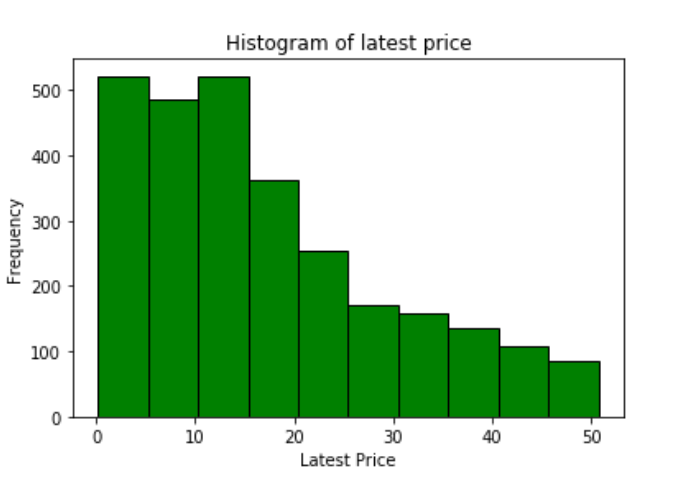
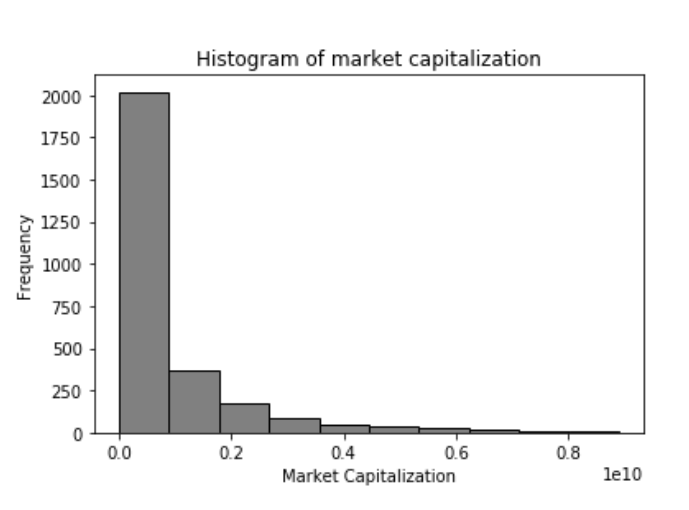
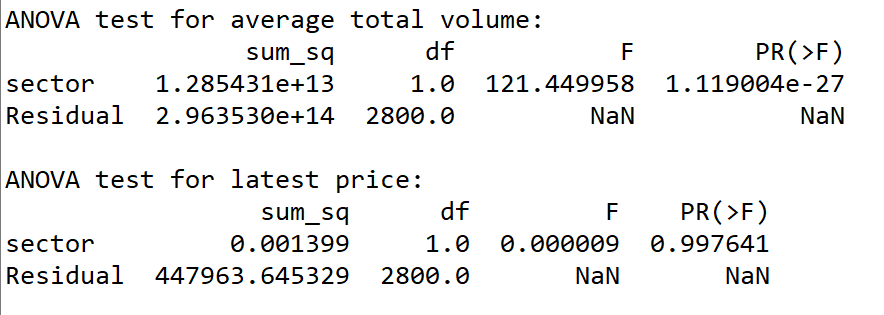
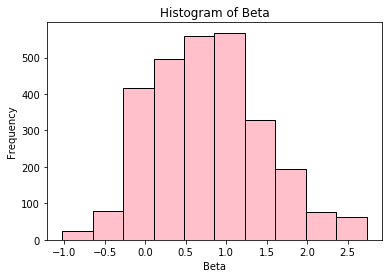


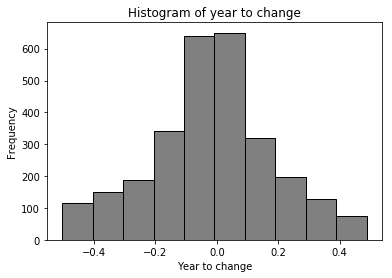



k-means clustering
KMeans(n_clusters=k)
hierarchical clustering
Ward's minimum variance method
by-hand clustering
label each sector by proportion
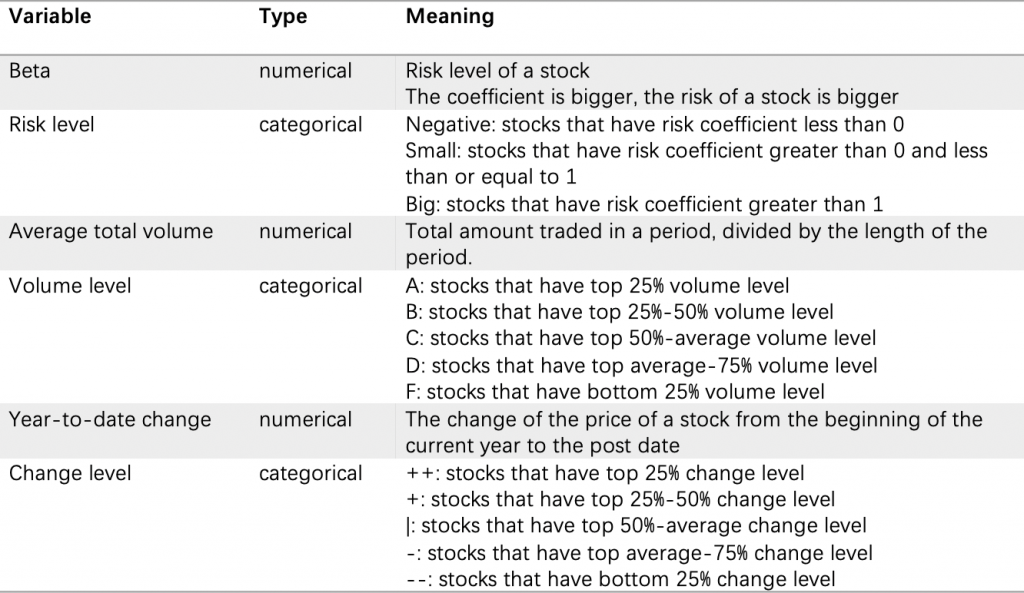
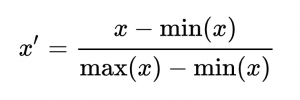

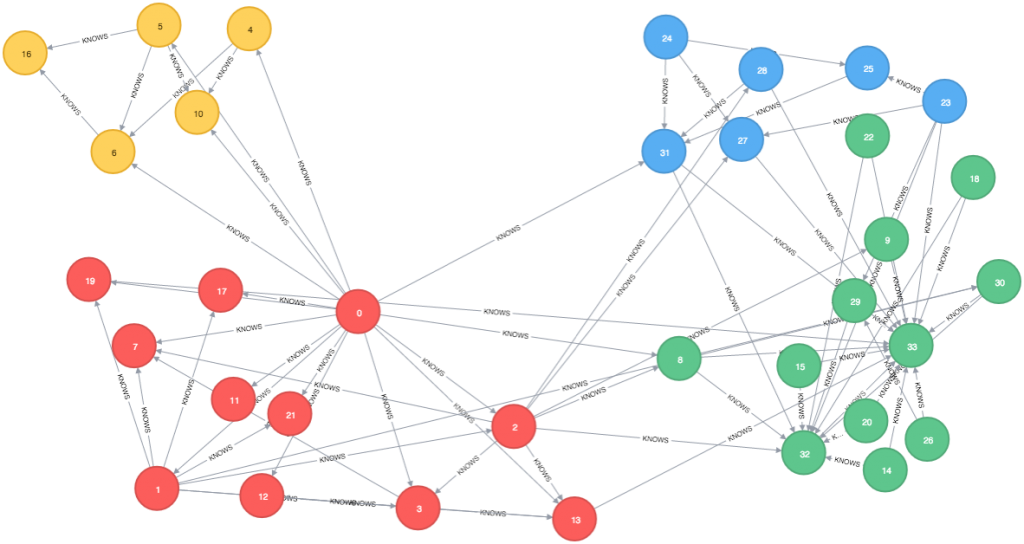
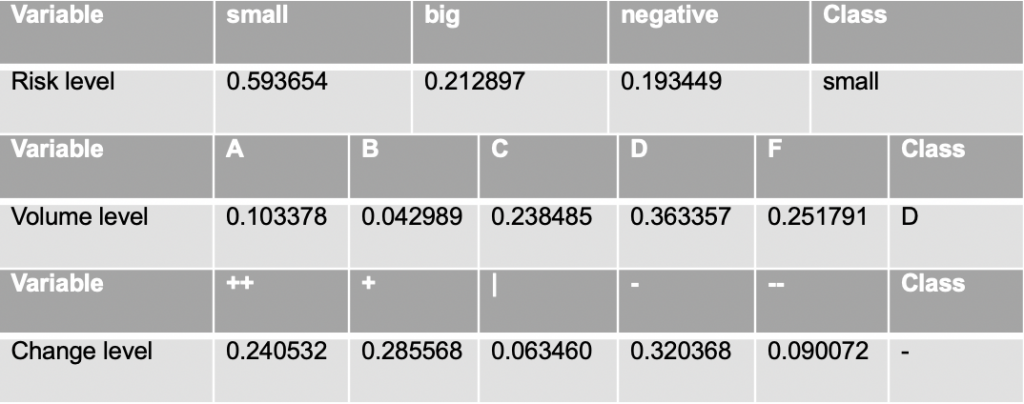
KMeans(n_clusters=k)
Ward's minimum variance method
label each sector by proportion